Why do we need Checkpoints ?
Whenever transaction logs are created in a real-time environment, it eats up lots of storage space. Also keeping track of every update and its maintenance may increase the physical space of the system. Eventually, the transaction log file may not be handled as the size keeps growing. This can be addressed with checkpoints. The methodology utilized for removing all previous transaction logs and storing them in permanent storage is called a Checkpoint.
What is a Checkpoint ?
The checkpoint is used to declare a point before which the DBMS was in the consistent state, and all transactions were committed. During transaction execution, such checkpoints are traced. After execution, transaction log files will be created.
Upon reaching the savepoint/checkpoint, the log file is destroyed by saving its update to the database. Then a new log is created with upcoming execution operations of the transaction and it will be updated until the next checkpoint and the process continues.
How to use Checkpoints in database ?
Steps :
- Write begin_checkpoint record into log.
- Collect checkpoint data in the stable storage.
- Write end_checkpoint record into log.
The behavior when the system crashes and recovers when concurrent transactions are executed is shown below –

Understanding Checkpoints in multiple Transactions
- The recovery system reads the logs backward from the end to the last checkpoint i.e. from T4 to T1.
- It will keep track of two lists – Undo and Redo.
- Whenever there is a log with instruction <Tn, start>and <Tn, commit> or only <Tn, commit> then it will put that transaction in Redo List. T2 and T3 contain <Tn, Start> and <Tn, Commit> whereas T1 will have only <Tn, Commit>. Here, T1, T2, and T3 are in the redo list.
- Whenever a log record with no instruction of commit or abort is found, that transaction is put to Undo List <Here, T4 has <Tn, Start> but no <Tn, commit> as it is an ongoing transaction. T4 will be put in the undo list.
All the transactions in the redo-list are deleted with their previous logs and then redone before saving their logs. All the transactions in the undo-list are undone and their logs are deleted.
Relevance of Checkpoints :
A checkpoint is a feature that adds a value of C in ACID-compliant to RDBMS. A checkpoint is used for recovery if there is an unexpected shutdown in the database. Checkpoints work on some intervals and write all dirty pages (modified pages) from logs relay to data file from i.e from a buffer to physical disk. It is also known as the hardening of dirty pages. It is a dedicated process and runs automatically by SQL Server at specific intervals. The synchronization point between the database and transaction log is served with a checkpoint.
Advantages of using Checkpoints :
- It speeds up data recovery process.
- Most of the dbms products automatically checkpoints themselves.
- Checkpoint records in log file is used to prevent unnecessary redo operations.
- Since dirty pages are flushed out continuously in the background, it has very low overhead and can be done frequently.
Real-Time Applications of Checkpoints :
- Whenever an application is tested in real-time environment that may have modified the database, it is verified and validated using checkpoints.
- Checkpoints are used to create backups and recovery prior to applying any updates in the database.
- The recovery system is used to return the database to the checkpoint state.
Checkpoint
- The checkpoint is a type of mechanism where all the previous logs are removed from the system and permanently stored in the storage disk.
- The checkpoint is like a bookmark. While the execution of the transaction, such checkpoints are marked, and the transaction is executed then using the steps of the transaction, the log files will be created.
- When it reaches to the checkpoint, then the transaction will be updated into the database, and till that point, the entire log file will be removed from the file. Then the log file is updated with the new step of transaction till next checkpoint and so on.
- The checkpoint is used to declare a point before which the DBMS was in the consistent state, and all transactions were committed.
Recovery using Checkpoint
In the following manner, a recovery system recovers the database from this failure:
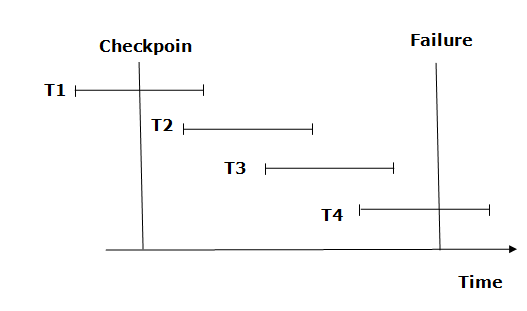
- The recovery system reads log files from the end to start. It reads log files from T4 to T1.
- Recovery system maintains two lists, a redo-list, and an undo-list.
- The transaction is put into redo state if the recovery system sees a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>. In the redo-list and their previous list, all the transactions are removed and then redone before saving their logs.
- For example: In the log file, transaction T2 and T3 will have <Tn, Start> and <Tn, Commit>. The T1 transaction will have only <Tn, commit> in the log file. That's why the transaction is committed after the checkpoint is crossed. Hence it puts T1, T2 and T3 transaction into redo list.
- The transaction is put into undo state if the recovery system sees a log with <Tn, Start> but no commit or abort log found. In the undo-list, all the transactions are undone, and their logs are removed.
- For example: Transaction T4 will have <Tn, Start>. So T4 will be put into undo list since this transaction is not yet complete and failed amid.