Cluster file organization
- When the two or more records are stored in the same file, it is known as clusters. These files will have two or more tables in the same data block, and key attributes which are used to map these tables together are stored only once.
- This method reduces the cost of searching for various records in different files.
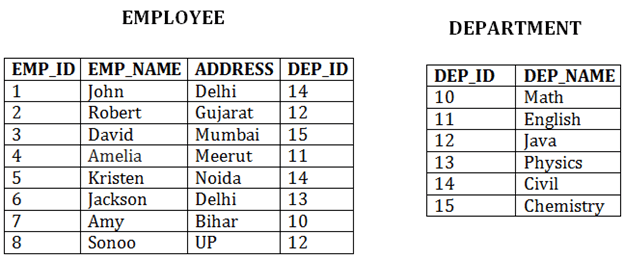
- The cluster file organization is used when there is a frequent need for joining the tables with the same condition. These joins will give only a few records from both tables. In the given example, we are retrieving the record for only particular departments. This method can't be used to retrieve the record for the entire department.
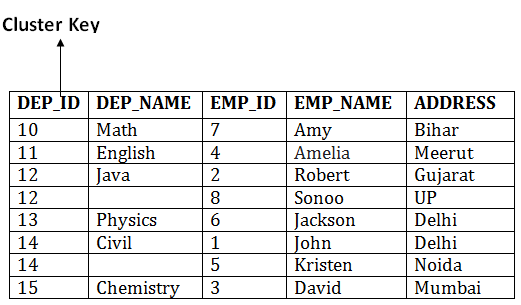
In this method, we can directly insert, update or delete any record. Data is sorted based on the key with which searching is done. Cluster key is a type of key with which joining of the table is performed.
Types of Cluster file organization:
Cluster file organization is of two types:
1. Indexed Clusters:
In indexed cluster, records are grouped based on the cluster key and stored together. The above EMPLOYEE and DEPARTMENT relationship is an example of an indexed cluster. Here, all the records are grouped based on the cluster key- DEP_ID and all the records are grouped.
2. Hash Clusters:
It is similar to the indexed cluster. In hash cluster, instead of storing the records based on the cluster key, we generate the value of the hash key for the cluster key and store the records with the same hash key value.
Pros of Cluster File Organization
- When there are many requests for connecting tables with the same joining condition, the cluster file organization is employed.
- Whenever there is a mapping of 1:M between the tables, it produces the most efficient output.
Cons of Cluster File Organization
- For a very large database, this approach has a low performance.
- If the joining condition changes, this method will no longer work. When we update the joining condition, traversing the file takes a long time.
- For a table with a 1:1 condition, this technique is ineffective.